特征向量与多元正态分布
1. 特征向量
a . a. a . 特征向量的定义如下:给定一个矩阵 A A A v v v A v = λ v Av=\lambda v A v = λ v v v v A A A
特征向量的几何意义如下:它把矩阵 A A A λ \lambda λ
b . b. b . 下面我们讲解一下如何从指定的特征向量和特征值,反向构造出一个对称矩阵 A A A :
首先,我们构造一个特殊的坐标系(Orthonormal Coordinate System):我们选择 n n n n n n v 1 , … , v n v_1,\dots,v_n v 1 , … , v n
互相正交(mutually orthogonal):任意两个不同的向量 v i v_i v i v j v_j v j
单位向量(unit vectors):每个向量自身的长度都为 1。
然后我们将这 n n n n × n n × n n × n V V V
V V T = I VV^T=I V V T = I V V V V V T = I VV^T=I V V T = I V T = V − 1 V^T=V^{-1} V T = V − 1
我们再选择 n n n λ 1 , λ 2 , … , λ n λ_1, λ_2, \dots, λ_n λ 1 , λ 2 , … , λ n n × n n \times n n × n Λ \Lambda Λ
我们将针对单个向量的 A v = λ v Av=\lambda v A v = λ v
A V = V Λ AV=V \Lambda A V = V Λ 这个矩阵形式一次性描述了 n n n V − 1 V^{-1} V − 1
A V V − 1 = A I = V Λ V − 1 ⇒ A = V Λ V − 1 AVV^{-1}=AI=V\Lambda V^{-1} \Rightarrow A=V\Lambda V^{-1} A V V − 1 = A I = V Λ V − 1 ⇒ A = V Λ V − 1 也即:
A = ∑ i = 1 n λ i v i v i T A=\sum_{i=1}^n\lambda_iv_iv_i^T A = i = 1 ∑ n λ i v i v i T 这个公式即是特征分解(Eigendecomposition)。它表明,任何一个实对称矩阵 A A A V V V Λ Λ Λ V V V V T V^T V T 。而求和形式的公式表明 A A A n n n v i ⋅ v i T v_i \cdot v_i^T v i ⋅ v i T λ i λ_i λ i
这里面的不同矩阵的几何意义如下:
V V V Σ − 1 \Sigma^{-1} Σ − 1 V V V 旋转 。Λ \Lambda Λ Λ \Lambda Λ λ i \lambda_i λ i Λ \Lambda Λ 缩放/拉伸 。
2. 各向异性高斯分布
一个各向异性的二维高斯分布就像一个被“压扁”或“拉伸”了的椭圆形山丘,其等高线是一系列同心椭圆。这意味着数据在某些方向上的方差比其他方向上更大 。
a . a. a . 多元高斯分布的概率密度函数如下:
X ∼ N ( μ , Σ ) , f ( x ) = 1 ( 2 π ) d / 2 ∣ Σ ∣ exp ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) X\sim\mathcal{N}(\mu ,\Sigma),\qquad
f(x)=\frac{1}{(2\pi)^{d/2}\,\sqrt{|\Sigma|}}\exp\left(-\frac{1}{2}(x-\mu )^T{\Sigma}^{-1}(x-\mu )\right) X ∼ N ( μ , Σ ) , f ( x ) = ( 2 π ) d /2 ∣Σ∣ 1 exp ( − 2 1 ( x − μ ) T Σ − 1 ( x − μ ) ) b . b. b . 我们将多元高斯分布的式子写成如下形式:
f ( x ) = n ( q ( x ) ) , q ( x ) = ( x − μ ) T Σ − 1 ( x − μ ) f(x)=n\bigl(q(x)\bigr),\qquad
q(x)=(x-\mu )^T{\Sigma}^{-1}(x-\mu ) f ( x ) = n ( q ( x ) ) , q ( x ) = ( x − μ ) T Σ − 1 ( x − μ ) 我们对 q ( x ) q(x) q ( x ) Σ \Sigma Σ Σ \Sigma Σ
Σ − 1 = V Λ V − 1 \Sigma^{-1}= V \Lambda V^{-1} Σ − 1 = V Λ V − 1 并令 x ′ = ( x − μ ) x'=(x-\mu ) x ′ = ( x − μ )
q ( x ) = x ′ V Λ V − 1 x ′ T = ( x ′ V ) Λ ( x ′ V ) T q(x)=x'V\Lambda V^{-1} x'^{T}=(x'V)\Lambda(x'V)^T q ( x ) = x ′ V Λ V − 1 x ′ T = ( x ′ V ) Λ ( x ′ V ) T 令 Y = V T x ′ Y=V^Tx' Y = V T x ′ 新的坐标轴与 Σ − 1 \Sigma ^{-1} Σ − 1 。则:
q ( Y ) = Y T Λ Y q(Y)=Y^T\Lambda Y q ( Y ) = Y T Λ Y 也即:
q ( Y ) = ∑ i = 1 n λ i y i 2 q(Y)=\sum_{i=1}^{n}\lambda_i y_i^2 q ( Y ) = i = 1 ∑ n λ i y i 2 我们将二次型的分布想象成一个“碗”,那么:
碗的方向由精度矩阵 Σ − 1 \Sigma⁻¹ Σ − 1 V V V 。这些特征向量就是碗的主轴方向,也就是椭圆等高线的长轴和短轴所在的方向。
碗的陡峭程度由精度矩阵 Σ − 1 Σ⁻¹ Σ − 1 Λ Λ Λ λ i λᵢ λ i 。大特征值 λ i λᵢ λ i v i vᵢ v i
而另一个函数 n n n q ( x ) q(x) q ( x )
c . c. c . q ( x ‘ ) q(x‘) q ( x ‘ ) 我们引入精度矩阵的平方根 Σ − 1 2 \Sigma ^{-\frac{1}{2}} Σ − 2 1 Σ − 1 \Sigma ^{-1} Σ − 1 V Λ V − 1 V\Lambda V^{-1} V Λ V − 1 Λ \Lambda Λ
Σ − 1 2 = V Λ 1 2 V T \Sigma ^{-\frac{1}{2}}=V\Lambda^{\frac{1}{2}}V^T Σ − 2 1 = V Λ 2 1 V T 我们将 q ( x ′ ) q(x') q ( x ′ )
q ( x ′ ) = x ′ Σ − 1 x ′ T = ( x ′ Σ − 1 2 ) ( Σ − 1 2 x ′ T ) = ( x ′ Σ − 1 2 ) ( x ′ Σ − 1 2 ) T \begin{aligned}
q(x') &= x' \Sigma^{-1} x'^{T} \\
&= (x'\Sigma^{-\tfrac{1}{2}})(\Sigma^{-\tfrac{1}{2}} x'^{T}) \\
&= (x'\Sigma^{-\tfrac{1}{2}})\bigl(x'\Sigma^{-\tfrac{1}{2}}\bigr)^{T}
\end{aligned} q ( x ′ ) = x ′ Σ − 1 x ′ T = ( x ′ Σ − 2 1 ) ( Σ − 2 1 x ′ T ) = ( x ′ Σ − 2 1 ) ( x ′ Σ − 2 1 ) T 令 y = x ′ Σ − 1 2 y=x'\Sigma^{-\tfrac{1}{2}} y = x ′ Σ − 2 1
q ( x ′ ) = y y T = ∥ y ∥ 2 q(x')=yy^T=\|y\| ^2 q ( x ′ ) = y y T = ∥ y ∥ 2 这是一个很重要的发现。原本在 x ′ x' x ′ Σ − 1 Σ⁻¹ Σ − 1 q ( x ) q(x) q ( x ) y = Σ 1 2 ( x ′ − μ ) y = \Sigma^{\frac{1}{2}}(x' - \mu ) y = Σ 2 1 ( x ′ − μ ) y y y 标准欧几里得距离的平方 。这在空间中表示一个以原点为球心的球面。
因此,Σ − 1 Σ⁻¹ Σ − 1 等高线的椭球形状 ,而 Σ 1 2 \Sigma^{\frac{1}{2}} Σ 2 1 定义了一个线性变换、使这个椭球变回一个完美的单位球体 。
3. 机器学习中的数据预处理
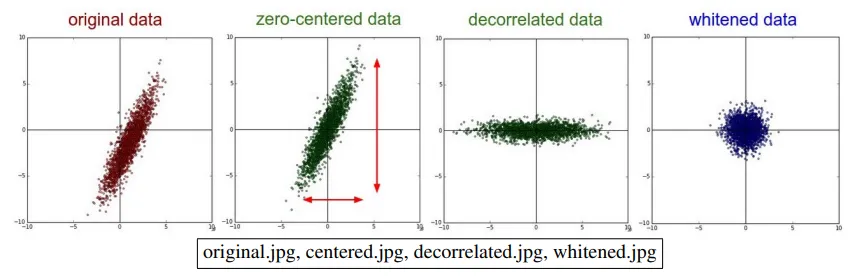
由我们对精度矩阵的一系列变换,我们可以抽象出在机器学习中常用的数据处理流程。假设我们的样本矩阵 X X X n × d n \times d n × d
首先我们对所有数据点进行中心化(Centering) X ˙ = X − μ \dot{X} = X - \mu X ˙ = X − μ ,变换后的数据点中心改变、其余性质不变。
注意到由协方差定义:
cov = 1 n ∑ ∑ ( x i j − μ j ) ⋅ ( x i k − μ k ) \text{cov}=\frac{1}{n}\sum\sum(x_{ij}-\mu _j)\cdot(x_{ik}-\mu _k) cov = n 1 ∑∑ ( x ij − μ j ) ⋅ ( x ik − μ k )
在中心化后的数据矩阵中,这一系列向量乘积正是 X ˙ T X ˙ \dot{X}^T\dot{X} X ˙ T X ˙ X ˙ T \dot{X}^T X ˙ T d × n d\times n d × n d × d d \times d d × d
cov = 1 n X ˙ T X ˙ \text{cov}=\frac{1}{n}\dot{X}^T\dot{X} cov = n 1 X ˙ T X ˙ 经过中心化后,数据云可能仍然是“倾斜”的(即特征之间存在相关性 ),形状是一个椭球。我们执行 Z = X ˙ V Z=\dot{X}V Z = X ˙ V ,其中 V V V Var ( R ) \text{Var}(R) Var ( R )
这是一个旋转操作。协方差矩阵的特征向量指出了数据椭球的各个主轴方向 。将数据乘以 V V V 于将整个坐标系旋转,使新的坐标轴与椭球的主轴对齐 。在新的坐标系下,新数据 Z Z Z Var ( Z ) \text{Var}(Z) Var ( Z ) Λ Λ Λ
由于特征值矩阵的特征值 Λ i i \Lambda_{ii} Λ ii 在不同轴上的“半径”还是不一样的 。因此我们对它进行 球化 (Sphering) 操作,令 W = X ˙ ⋅ Var(R) 1 2 W=\dot{X} \cdot \text{Var(R)}^{\frac{1}{2}} W = X ˙ ⋅ Var(R) 2 1 。这个变换将一个倾斜的椭球数据云,先旋转对齐坐标轴,然后沿着每个轴进行压缩或拉伸,直到每个轴上的“半径”都相等。最终,数据云变成一个完美的球形。
这些计算过程和我们之前对 Σ \Sigma Σ
注意,对于 LDA 和 QDA 这样的判别分析方法,它们不需要预先对数据进行球化。因为这些算法的核心就是直接对协方差矩阵 Σ Σ Σ 。它们的数学公式,尤其是马氏距离 ( x − μ ) T Σ − 1 ( x − μ ) (x − \mu )^T \Sigma^{-1} (x − \mu ) ( x − μ ) T Σ − 1 ( x − μ ) 内在地、自动地处理了数据的形状、方向和尺度问题 。
4. 协方差的一些性质
这里只简单罗列一些性质,具体计算之后有机会再详细写。
如果两个变量相互独立,那么它们的协方差一定为零。但是反过来并不成立,因为协方差为零只能说明它们之间没有线性关系 ,但它们可能存在非线性关系(例如 y = x 2 y = x² y = x 2
对于一个服从多元高斯分布的向量,如果它的两个分量 R i Rᵢ R i R j Rⱼ R j 可以断定它们一定是相互独立的 。
当一个多元高斯分布的协方差矩阵 Σ Σ Σ f ( x ) f(x) f ( x ) d d d Σ \Sigma Σ 数据的分布没有“倾斜”,它的等高线椭球(或椭圆)的主轴是与坐标轴对齐的 。椭球在每个坐标轴方向上的“半径”(拉伸程度)由 Σ Σ Σ
如果某个多元高斯分布的协方差矩阵 Σ Σ Σ 做一个坐标系变换,变换到由 Σ Σ Σ 。在这个新的特征向量坐标系里,变量之间就变得不相关了,协方差矩阵也变成了对角矩阵 Λ \Lambda Λ